
Intro
얼마 전 전례 없던 데이터센터(이하 IDC) 화재와 이로 인한 장애로 전국이 떠들썩했습니다. 초연결시대에 네트워크 장애는 새로운 유형의 재난이라는 인식도 생겨나고 있습니다. 그 만큼 많은 사람들이 크고, 작은 영향을 받았고 향후 더 큰 천재지변이나 전쟁 등과 같은 유사시 대비에 대한 사회적인 논의도 커지고 있습니다.
판교 SK C&C IDC에서 벌어진 화재는 카카오, 네이버 등 해당 IDC 임대 기업 서비스에 영향을 미쳤습니다. 특히 이번 사고는 전기실 배터리에서 발생한 화재로 진압이 더욱 까다로웠고 추가적인 손실, 즉 서버 훼손으로 인한 데이터 유실이나 인명 피해를 예방하기 위해 서버 전체 전원을 차단할 수 밖에 없었다고 합니다.
갑작스럽게 발생한 물리적인 사고이다 보니 발생 직후 단기간의 장애는 불가피했습니다. 이로 인해 네이버 일부 서비스에도 영향이 있었으나, 대부분 사고 발생 30분 이내, 길게는 4시간 안에 전면 정상화 되었습니다. 특히 핵심서비스에 큰 영향 없이 이용자 피해를 최소화 할 수 있었습니다. 네이버는 서비스 연속성 유지를 위해 평소 어떻게 대비하고 있으며, 당시에는 어떻게 대응했는지 궁금해 하시는 분들이 많이 계십니다.
네이버클라우드 SIM(Service Infra Manager)이자 BCP(Business Continuity Plan)를 담당하시는 김도현님과 인터뷰를 진행했습니다. 응당 해야하는 역할을 한 것 뿐이라며 조심스러운 입장을 취하셨으나, 이번 일을 계기로 DR(재해복구) 구성에 관심을 갖게 된 분들께 도움이 되기를 바란다며 어렵게 인터뷰에 응해 주셨습니다.

Interview
A. 저는 네이버의 인증/미디어 서비스 등을 담당하는 SIM(Service Infra Manager)*이자 BCP-TF(Business Continuity Plan TF, 업무 연속성 계획을 수립하고 재해 발생시 컨트롤 하는 조직)에서 서비스 영역을 담당하고 있습니다. BCP는 업무 연속성 계획으로 어떠한 상황에서도 서비스를 지속하기 위한 목적으로 수립되었으며, 재해 유형별 대응 절차가 메뉴얼화 되어 있습니다. 이번 사고 때도 BCP 절차에 따라 대응했습니다.
* SIM : 각 서비스별 인프라 담당 책임자로 서비스를 구성/운영하기 위한 모든 인프라를 관리하며, 개발/기획/서비스 부서와의 단일 접점으로서의 역할을 수행합니다.
네이버는 판교 SK C&C IDC에 서버 2만 2천대 이상을 운영하고 있습니다. 화재 발생이 감지되자마자, 판교 IDC로 들어오는 트래픽을 즉시 제한하고, 이중화된 다른 IDC로 우회하는 작업이 전체적으로 진행되었습니다.
네이버 서비스에는 시스템 복구와 서비스 연속성 유지를 위한 7단계의 서비스/인프라 이중화 체계가 적용되어 있습니다. 화재 발생 직후, 각 서비스는 서비스 등급에 따라 사전에 마련된 복구 절차에 의해 자동 또는 수동으로 이중화 조치된 타 센터 인프라로 전환되었습니다. 주요 서비스는 이중화된 인프라로 자동 전환되어 서비스 이용에 영향이 없었으며, 주요 서비스 외 일부 기능들은 다른 IDC에 상시 확보하고 있는 상면 및 장비로 즉시 수동 전환되었습니다.
저를 포함한 SIM(Service Infra Manager)들은 서비스별 영향도를 즉시 파악하고 개발팀과 대응 방안을 수립했습니다. 이는 모두 사전에 준비된 대응 Level 및 절차에 의해 진행된 것으로, 그 덕분에 지체없이 복구할 수 있었습니다.
네이버는 춘천 데이터센터 ‘각’을 포함하여 국내에만 6개의 데이터센터를 운영하고 있습니다. SIM들은 기본적으로 자신이 담당하는 서비스의 구조와 인프라 현황, SDA(Service Delivery Architecture)를 파악하고 있으며, 이를 기반으로 최소 연 2회 이상 모든 서비스들의 이중화 현황을 확인하고 있기 때문에 이번과 같은 재해 상황에 빠른 대응이 가능했습니다.
네이버의 서비스 이중화 및 IDC 이중화 체계는 다음과 같습니다.
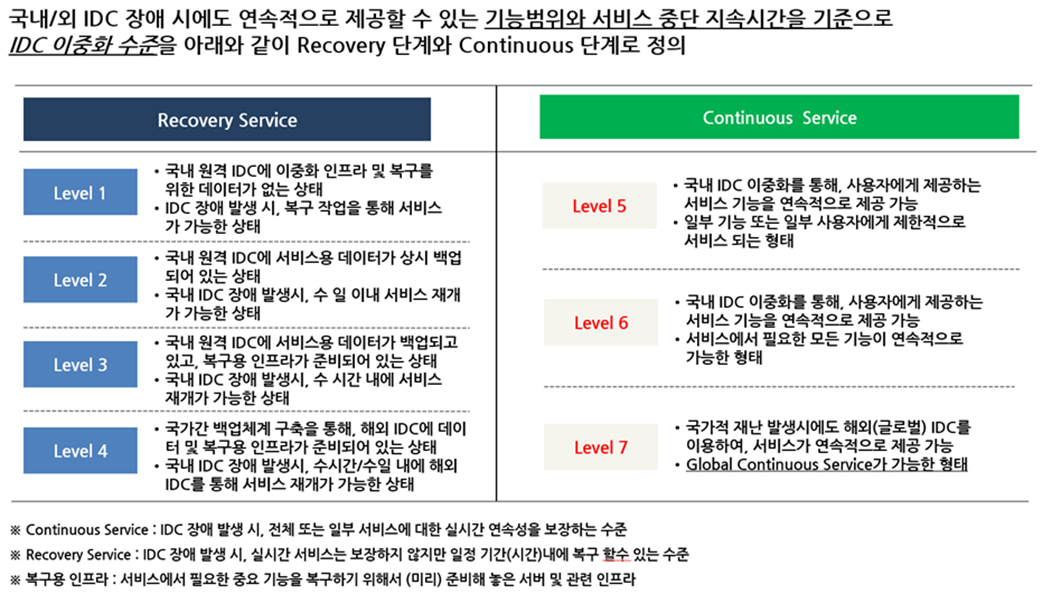
네이버 포털을 포함하여 대국민이 이용하는 모든 주요 서비스는 서비스 복구(Recovery Service) Level 3 수준을 달성하도록 운영하고 있습니다. 국내 원격 IDC에 서비스용 데이터가 백업되어 있고 복구 인프라도 준비되어 있어 주 IDC에 재해가 발생하더라도 수 시간 내 복구 및 서비스 재개가 가능한 수준을 유지하는 것입니다.
서비스 연속성(Continuity Service)에 있어서는 Level 5를 달성하고 있으며, 지속적으로 Level 6을 적용해 나가고 있습니다. 서비스를 운영하는 특정 IDC에 문제가 발생하더라도 이중화 된 IDC를 통해 서비스 연속 이용이 가능한 수준을 유지하는 것입니다.
금번 판교 SK C&C 데이터센터 화재 사고에서도 서비스 복구(Service Recovery) Level 3와 서비스 연속성(Service Continuity) Level 5 & 6 수준에서 대응이 이루어졌습니다.
A. 이번 사고를 계기로 HA(High Availability)나 DR(Disaster Recovery) 관련해서 많이 들어보셨을 텐데요.

네이버 서비스에는 일반적으로 알고 계신 수준의 DR 이상의 고도화된 대비와 물리적인 장치가 적용되어 있습니다. 대한민국 국민 대부분이 사용하는 서비스이기도 하고, 네이버 메인 페이지나 검색플랫폼 같은 경우 비상시에 그 중요성이 더욱 커지는 서비스이기 때문입니다.
IDC의 경우 네이버클라우드의 자체 기술로 운영하는 데이터센터 ‘각’ 외에도 국내외 복수 IDC를 운영하고 있고, 상당수의 서비스가 쿠버네티스 환경에서 동작합니다. 데이터는 이중화 및 IDC간 상호 백업을 유지하고 있습니다. 단순하게 서비스 패키지와 데이터를 백업하여 두는 것 이상의 대비를 하고 있다고 보시면 됩니다.
A. 단순히 데이터센터를 여러 개 사용하는 것이 아니라 인프라와 플랫폼을 안전하게 운영할 수 있는 역량이 필요합니다.
네이버 서비스 접속에는 GSLB(Global Server Load Balancing) 기술이 적용되어 있습니다. 장애가 없는 상황에서는 가장 가깝고 빠른 IDC로 연결해주는 역할을 수행하지만, GSLB는 해당 IDC 트래픽이 정상적인 상황인지 지속적으로 체크하는 역할도 수행해요. 그래서 특정 IDC에 문제가 생긴 경우 자동으로 해당 IDC를 차단하고 다른 IDC로 트래픽을 보냅니다. (자동 Fail-Over) 네이버 포털, 검색, 페이, 회원플랫폼, 뉴스 등을 비롯한 네이버의 모든 서비스는 GSLB로 IDC를 이중화하여 active-active*로 운영하고 있고, 중요한 일부 서비스는 삼중화 구조로 대비하고 있습니다.
*Active-Active : 2대의 서버로 동시에 운영하는 방식, active-active 이중화가 되어 있다면 특정 시스템, 컴포넌트에 이슈가 발생하더라도 서비스를 연속적으로 운영할 수 있습니다. (비교) Active-Standby: 서버 2대 중 한 서버에서만 운영하고 다른 서버는 대기 상태로 두는 방식
다시 말해 네이버의 모든 주요 서비스들에는 다중화가 적용되어 있고, 다중 IDC 서로간 그리고 IDC 내부 네트워크는 메시 구조로 되어 있습니다. 메시 구조란 그물망과 같은 다대다 연결로 특정 IDC나 서버 이용이 불가능한 상황에도 서비스 연속성을 유지합니다. 인프라 구조 뿐 아니라 데이터가 오가는 물리적인 통로인 메인 백본과 말단 스위치를 포함한 모든 장비들도 이중화하여 대비하고 있습니다.
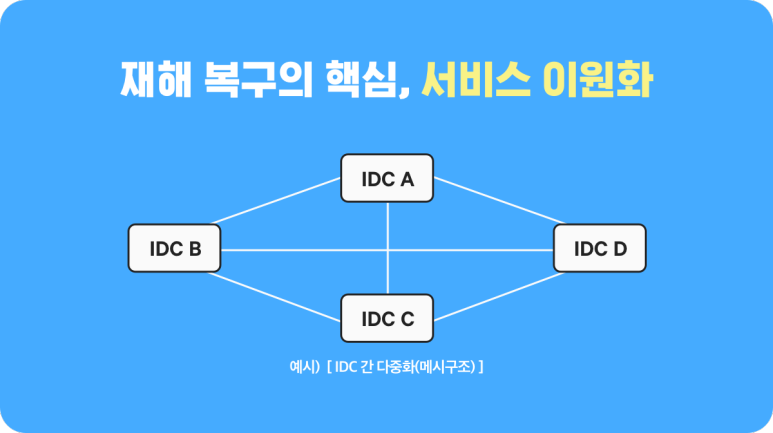
< IDC 메시 구조 예시 >
A. 네이버의 각 서비스와 플랫폼은 컴포넌트별로 모듈화하여 다중 분산 인프라로 구성합니다.
분산시스템의 장점은 두 가지 측면으로 볼 수 있어요. 하나는 특정 서버에서 운영하던 서비스에 장애가 발생하였을 때 다른 서버에 신속하게 배포하여 서비스를 재개할 수 있다는 것입니다. 해당 모듈이 있는 특정 IDC에 재해가 발생해도 해당 모듈만 다른 IDC에서 복구하면 되기 때문에 규모나 시간면에서 매우 효율적입니다. 특히 일부 서비스는 쿠버네티스 기반으로 구성되어 해당 프로젝트 소스를 빠르게 배포하여 서비스 정상화가 가능합니다.
두 번째는 특정 컴포넌트에 장애가 발생하였을 때 그 영향을 국지적으로 최소화 할 수 있습니다. 예를 들어, 이번에 뉴스 댓글에 오류가 생겨 복구하는 동안에도 댓글을 제외한 다른 모든 뉴스 서비스 기능에는 문제가 없었습니다.
A. 서비스 구동 환경과 유저 데이터 모두가 대비되어 있어야 DR이라고 할 수 있겠죠.
일반적으로 DBMS에 유저 데이터를 저장하며, 각 DBMS별로 이중화 기술을 적용하여 서비스 하고 있습니다. 그리고 모든 DB는 IDC 간 상호 백업을 유지하고 있습니다. 아주 중요한 데이터는 3중으로 보관하기도 합니다. 데이터 백업은 아주 기본적인 사항이라고도 할 수 있는데요.
예를 들어, DBMS 중 MYSQL DB는 MMM이라는 기술로 이중화합니다. 특히 네이버는 독자적으로 커스텀한 MMM을 사용하고 있습니다. 서비스에 최적화된 데이터 이중화 및 백업 체계를 가지고 있기 때문에 문제가 생기더라도 훨씬 원활하고 안전하게 대응할 수 있다고 생각하시면 됩니다.
A. 앞서 BCP(Business Continuity Plan)에 대해 말씀을 드렸는데, 업무 연속성 계획은 형식적인 절차나 문서가 아닙니다.
네이버 전체 서비스에 대한 인프라 운영을 담당하는 네이버클라우드는 지속적인 BCP 업데이트는 물론 실제로 연 2회 이상 모의 훈련을 실시하고 있습니다. BCP에는 비상연락망이나 즉각적인 보고 체계 뿐만 아니라 부서별 액션 아이템도 상세하게 규정하고 있는데요. 이번 대응 역시 BCP 메뉴얼에 따라 이루어졌습니다.
A. 과거 10년 전 까지만 해도 DR의 필요성은 대기업이나 금융권에서나 공감하는 이슈였습니다. 비용도 많이 들고 운영을 위한 전문 인력도 필요하기 때문입니다. 최근에는 클라우드 인프라를 활용하여 중견, 중소 기업도 비교적 손쉽게 DR 구성이 가능합니다. 기존 DR 구축이 많은 비용을 수반한 투자의 개념이었다면, 네이버 클라우드 플랫폼에서 작은 규모와 합리적인 비용으로 쉽고 빠르게 시작할 수 있습니다.

A. 사실 천재지변이란 불가항력입니다. 최근에 발생한 화재도 사람이 컨트롤할 수 있는 문제가 아니었습니다. 서비스에 문제가 전혀 발생하지 않았더라면 좋았겠지만, 동료들과 합심하여 단기간에 복구할 수 있어 인프라 담당자로서 보람을 느꼈습니다.
앞서 말씀드린 장애 대비, 이중화에는 많은 리소스가 필요합니다. 사고가 나지 않으면 티가 잘 나지 않는 것도 사실입니다. 하지만 만약의 상황을 대비하고, 투자하는 것은 대국민 서비스를 운영하는 기업의 사회적 책임이라고 생각합니다. 네이버 서비스가 멈추어서는 안 된다는 마인드가 구성원들에게 공유되어 있고, 항상 안정적인 서비스를 제공하기 위해 노력하고 있습니다. 앞으로도 네이버가 신뢰할 수 있는 플랫폼이 될 수 있도록 더욱 노력하겠습니다.